My eyes just glaze over when I see every file being listed and its purpose. Just because you CAN do that with LLMs doesn’t mean you should. What are you really trying to communicate?
I was under the impression the purpose of that is to give an LLM a cheap (in terms of context window) understanding of a repo, and not at all for the benefit of humans?
Whether that's effective is another matter, even if the LLM generating the list does so correctly and updates the list consistently
Sooo it’s just streaming a game to your browser. What does this have to do with Dwarf Fortress? There’s tons of generic solutions like this that would work the same way for DF as well. It’s giving AI slop.
This is the sort of trademark violation where I can get behind proper enforcement. It's using the name of an unrelated project for advertisement (attention).
I've been sitting here trying to do sleepy morning train commute maths.
1billion scans per month, 50,000 scanners worldwide (!). 1 minute scan time. Lowers platform at 5cm/cm. FTA.
Globally, apparently in 2023 there were 250,000 spas worldwide. [0]
Their numbers would suggest these 1 billion people, getting scanned by 50k scanners, have each scanner doing 20k scans a month. 31 days, 24 hours, we have 744 hours in which to do these. That's 20k scans/744 hours, giving you 26.8 scans/hour. One scan'll be 2.2min. 2 minutes 14 seconds.
If this machine is 200cm big, lowers at 5cm a sec, that gives you 40seconds to lower. One minute to scan. 40 seconds to get you back up, presumably. Even if we're generous and double that, you're at 2 minutes just to lower, scan, and yeet you back up.
Giving you 14 seconds between scans. To clean, maintain, etc. Seems like this machine will output investor AI hype, bacteria, and false positives.
I linked the spa statistics because there's the question of how they'll even get the room for these machines but whatever.
I don't think this changes anything important, but my understanding is that the lowering is the scan -- you go through the ring, which captures data about the slice currently inside it. That gets you down to ~80s, which rounds to a minute (they say "about 5 cm/s").
Now, there's a lot of other reasons to be skeptical (e.g. there's no information on what all of this imaging could actually resolve), but please don't shoot the message.
Lots of folks in here calling out the "billion scans a month" and skipping over the "capable of" part.
They're not claiming they'll perform a billion scans. They're trying to build enough machines that if absolutely all of them were run at 100.00% capacity it would be theoretically possible to do a billion scans a month.
Yeah, that's not just 'cart before the horse', it's more like cart before the wheel. They make a bunch of extraordinary claims yet offer zero evidence, info or even a plausible hypothesis on how those claims might be possible at the scale, timeframe (2027) and unit economics implied. Thank goodness they really thought through the accent lighting for a calming user experience though. Otherwise, I might have been concerned they're not serious. </s>
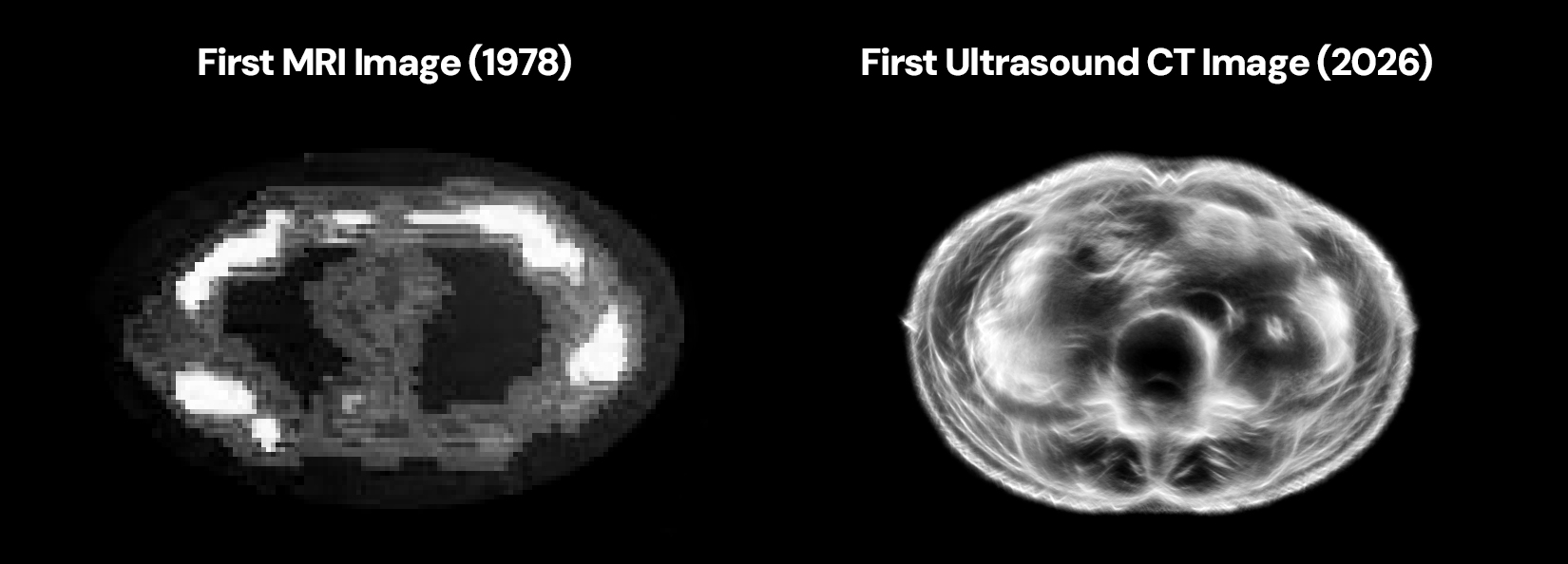
But they have a picture showing a higher resolution Ultrasound CT result than a 1978 MRI! Surely that's important and useful information by which we can judge their product.
I did see that. And it does look better. Okay, I'm sold! Sign me up for my spa visit including avocado facial peel, genital waxing and computed axial tomography ultrasound.
More seriously, I assumed that CT Ultrasound image is from Butterfly's actual FDA-approved handheld medical device, not the Midjourney 360 submerged ring - as there's no evidence that is working. Since the Midjourney site has no helpful information, I just asked a friendly AI to do a comparison of what's actually proven to work in the Butterfly chip which Midjourney licensed and this 360 degree, full body, submerged concept - and essentially what's not been proven to work are those three differences: 360 degree ring of 40 butterfly chips, full body at once (requiring solving distance and speed challenges as well as a massive signal processing problem to extract and denoise signal), and doing it submerged.
I don't believe any of the examples provided would have escaped an image classifier. The hypothetical where they did is one of gross incompetence IMO (and I don't think that's likely to be the case).
Even if you don't train on gore that's bad enough to trip an image classifier, the model learns the concept of "more [liquid/jam/syrup/chunks/etc.]" and that can generalize to creating gore that would trip the same classifier.
Right but if a classifier gets applied to the final output before the image is sent back to the user then it should catch that. Several remarkably accurate and very lightweight open weights models intended for moderation are freely available at this point.
Holy crap. Had to pick my jaw up off the floor. I hope you get some kind of acknowledgement or bounty for this. Kudos for having the willpower to resist sending a message to millions of people and sparking a global phenomenon!
To each their own, but I do it every day, nearly. I’m using wifi 6 though, so that might be the difference. 2.4Ghz might not be sufficient. There’s also very likely local faking on the device (Quest 3) that can rotate your vision before the new data arrives.
Either way, it’s pretty alright nowadays, at least in my experience.
Though time in the seat *might* be making it easier for me.
This is how most consumer vr used to be before the (oculus) quest, and it worked fine. The data path was massive with base stations etc. A lot of people did get motion sick, but its probably more to do with framerate, one would have thought
Not really, most were wired with zero latency. Wireless adapters existed but didn't do local "reprojection" aka rudimentary warping to absorb pose differences between when the sensor data was captured and new frames is being rendered.
Current Wi-Fi based streaming pipe mp4 frames and swing it around. That's slightly different from static raw frame wireless solutions before Oculus Quest.
I am a AI Researcher at a university. I tried Fable for my current project, but i feel it missunderstands me a bit to often. Now i don't know if i am using it wrong, or anthropic tries to slow my research. That model is a big no no.
{kind=link}
reply